Posts
-
Automate All the Things? Common Automation Pitfalls in IT
Automation is not a new concept by any means. It has been around since the industrial revolution and it is the main reason why we have become so efficient at producing “things” at an ever faster pace. It was first applied to the production of physical “things” such as cars and electronic devices. Today, IT and Software Engineering teams around the world rely on automation to keep up with increasing demands to reduce costs and minimize time to market.
-
Migrating from Wordpress to GitHub Pages
At the beginning of the new year, I decided to migrate my blog from Wordpress to Github Pages. Even though the process was pretty simple, thanks to a number of open-source tools, there were a couple of hurdles along the way, so I decided to create this step-by-step guide.
-
My Holiday Card Pipeline: A Visual Representation of the Effects of Work In Progress
It’s holiday time. Some people use this time of the year to reflect on the past. Others, prefer to look to the future and set goals for the new year. For me, well…for me it means sending holiday cards to friends and family.
-
Network Security - Part 7: Remote Access & VPNs
In today’s world, It’s very common for companies to have multiple offices around the world and to allow employees to work remotely. This desired for mobility must be taken into consideration when designing your network to ensure people can access company resources from anywhere, at anytime, and with a high degree of security. The most common remote access technology used today are Virtual Private Networks (VPNs).
-
Network Security - Part 6: Web Proxies
Let’s take a step back and look at the environment we have created so far. We have both network and host-based firewalls to control traffic flowing between different networks, especially traffic coming in from untrusted zones. We even added a DMZ to isolate publicly exposed services (such as web servers) from the rest of the environment. But what if one of our users goes to a malicious website and downloads malware that then spreads throughout your internal network? What if your CFO gets tricked into clicking on a phishing link and gives away his or her credentials to an attacker?
-
Network Security - Part 5: Network Segmentation (DMZ)
In Part 4 of this series, I talked about the importance of host-based firewalls to protect against lateral movement between host co-located on the same network. Though that was a great improvement, there are still some critical design issues with our network architecture:
-
Network Security - Part 4: Host Firewalls
So you spent thousands of dollars on a next-gen firewall.That means you are secure, right? Even though it is obvious that the answer to this question is no, many people believed otherwise not that long ago. Just because you spend money on security doesn’t mean that you’ll be secure. Network firewalls provide one layer of protection for your environment but they can be bypassed by experienced attackers, specially if the firewall is not configured properly. In fact, it’s not a matter of “if”, it’s a matter of “when”. What will you do when an attacker bypasses your firewall and compromises one of your endpoints?
-
Network Security - Part 3: Network Firewalls
A lot of people in the security industry have been talking about the de-perimeterisation of the network for a few years now. Even though attention has shifted away from prevention technologies and companies are investing more time, money, and effort into detection and response, the truth is that protecting the perimeter from external attacks is still relevant today. You might not be able to block every malicious packet from entering your network but if you can slow the attacker down you’ll have more time to detect them and respond to the attack before they get access to a critical system.
-
Network Security - Part 2: Network Services
In part 1 of this series we created the environment that we will be using in future posts. At the core of the network architecture is our pfSense router. Before we can start exploring all the security features that pfSense provides we need to configure some basic network services for our LAN (management) and OPT1 (internal) networks.
-
Network Security - Part 1: Setting Up Your Environment
A few months ago, I embarked on a journey to learn more about the fundamentals of network security. This is the first of a series of technical blog posts where I will try to cover some of the tools and techniques I learned along the way: network and host-based firewalls, web proxies, or intrusion detection systems among others.
-
Building an Ethical Hacking Lab
If you want to have a successful career in Information Security, building your own personal lab is essential. Not only it is likely to come up during technical interview questions but it will also be your personal geek playground. The lab is where you learn, discover, and have fun.
-
Building an Intel NUC HTPC with Kodi
Being the movie junkie that I am, I’ve wanted to build my own Home Theater PC (HTPC) for quite some time. This past Black Friday I saw a great Intel NUC combo deal on Newegg so I decided to give it a try. In this post I will show you how to assemble an Intel NUC5CPYH, how to install OpenELEC, and how to configure it so that you can get the best out of your HTPC.
-
OpenDJ Java SDK Testing: Part 2
A few weeks back I decided to write a blog post on how to efficiently test a Java application that uses the OpenDJ SDK to connect to an LDAP store (read post here). Since the scope was so big I had to break it down into two smaller posts. In this second part I will walk you through a sample maven-based application written in Java that uses Docker for integration testing.
-
OpenDJ Docker Image for Integration Testing
As I mentioned in my previous post I’ve been playing with Docker lately trying to build an OpenDJ image that I could use for integration testing. Before digging deeper into my testing strategy I decided to publish this short post to explain how such image can be created using a simple Dockerfile.
-
OpenDJ Java SDK Testing: Part 1
If you have ever used the OpenDJ Java SDK to connect to and OpenDJ Directory Server from your application chances are that you’ve asked yourself the following question: how the hell do I test this?
-
OpenAM12 Custom Authentication Chains
One of the cool features of JAAS (Java Authentication and Authorization Service), which is at the core of OpenAM’s authentication engine, is that it’s modular. Not only you can create your own authentication modules but you can also chain multiple modules together in a cascade fashion. This comes in handy when you want to implement some sort of strong authentication, such as 2-factor authentication flow, where you need to force the user to go through multiple authentication steps.
-
OpenAM 12 Custom Authentication: Error Messages
This is the first of a series of posts in which I plan to cover some tips and pitfalls involving the creation of custom authentication modules in OpenAM 12. One of the most common people ask me is how do I customize the error messages returned by the OpenAM’s authentication engine?. Today I will explain step-by-step how to add custom error messages to your authentication modules.
-
Follow up: Tomcat HA Cluster Automation using Ansible and Vagrant
In one of my previous posts I presented a solution to automate a Tomcat cluster installation using Ansible. One of the assumptions I made at the time was that the actual machines (physical or virtual) were already running and that Ansible could access them via SSH. Well, that might be true for a real production-like environment but what if you wanted to test this out on your local machine? Wouldn’t it be cool to spin up some virtual machines first and then use Ansible to provision them with the click of a button? Vagrant to the rescue!
-
Unit Testing Using Groovy, JUnit, and Maven
One of my clients had to use Groovy scripts to synchronize thousands of user identities between multiple data sources. When I started working on the project the development process looked similar to this:
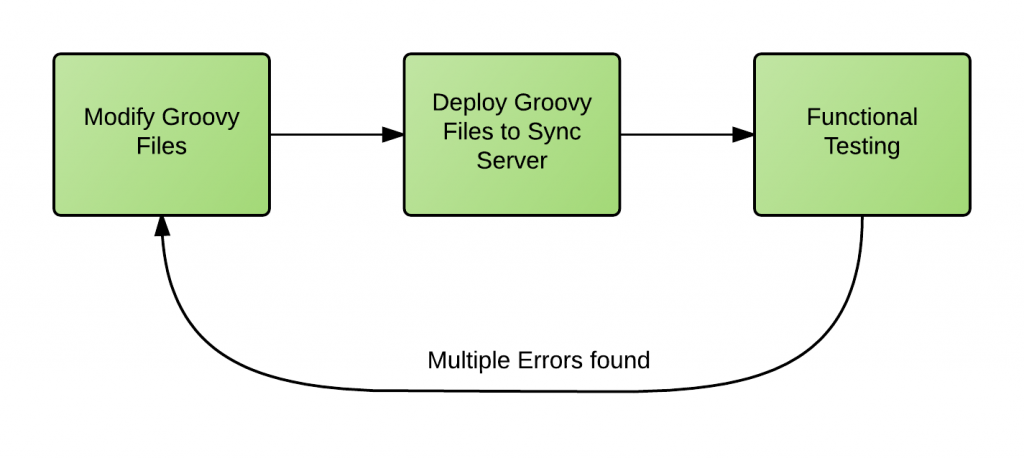
It's obvious that this process was far from being efficient. It was very time consuming and, most importantly, errors were caught too late in the development cycle making them very expensive to fix.
Over the years, I've learned to ask myself the following question over and over again: what can I do to make this process more efficient? The answer in this case was simple:
Test earlier. Test better.
-
Tomcat HA Cluster Automation using Ansible
For the last couple of weeks I've been playing with Ansible, a very powerful automation tool that lets you configure, and deploy applications to multiple remote servers with a single command.
subscribe via RSS